

Şirketler, ticari operasyonlarının normal seyrinde muazzam miktarda hassas veri üretir, saklar ve işler. Bu sebeple kuruluşların çoğu verilerini depolarken veya iş amaçlı kullanırken çeşitli güvenlik kontrolleri kullanır. Günümüzde bulut ortamlarının yaygınlaşmasıyla beraber kurum içi verilerin bulut sistemlerine dolayısıyla üçüncü parti ortamlara aktarılması çeşitli veri ihlali risklerini ve regülasyon zorunluluklarını beraberinde getirmiştir.
Kuruluşlar tarafından uygulanan çeşitli koruma önlemlerine rağmen, Kişisel Tanımlayıcı Bilgileri (PII) içeren veri ihlalleri, çeşitli sektörlerde hâlâ önemli mali kayıplara neden olmaktadır. IBM Security’nin 2023 Veri İhlalinin Maliyeti Raporu’na göre, Mart 2022 ile Mart 2023 arasında, güvenliği ihlal edilen müşteri ve çalışan bilgilerinin kuruluşlara kayıt başına 180 dolar maliyeti olduğu bildirilmektedir. Kurum dışına çıkacak verilerin korunması, maskelenmesi ve gerektiğinde gerçek veri ile ilişkilendirilmesi dünya çapındaki kuruluşlar için en önemli önceliklerden bir tanesidir. Bu sebeple veri anonimleştirme, her büyüklükteki işletme için giderek daha da belirginleşen ve önemi artan bir kavram haline gelmektedir. Veri anonimleştirme, bir veri kümesindeki kişisel olarak tanımlanabilir verilerin kaldırılmasını veya şifrelenmesini içeren bir bilgi temizleme yöntemidir. Veri anonimleştirmede amaç kişinin Kişisel Tanımlayıcı Bilgilerinin(PII) gizliliğini sağlamaktır. Anonimleştirme, kişisel veri ihlallerini önleyebilecek veya en azından ihlal edilen her kişisel veri kaydının maliyetini azaltabilecek en etkili veri koruma önlemlerinden biridir.
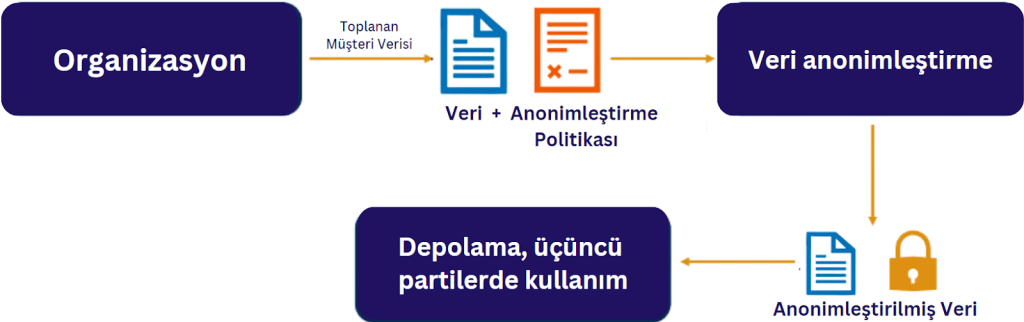
Veri Anonimleştirme Yöntemleri
Veri anonimleştirme yöntemleri, kullanıcı gizliliğini korurken veri setlerini kullanışlı kılmada önemli bir rol oynar. Ancak, her bir yöntemin kendi avantajları ve zorlukları vardır. Hangi yöntemin kullanılacağı, işletme ihtiyaçlarına ve veri setinin özelliklerine bağlı olarak dikkatlice seçilmelidir.
Veri Maskeleme (Data Masking)
Veri maskeleme, orijinal harflerini ve sayılarını değiştirerek verileri gizleme işlemidir. Veri maskeleme, gizli bilgileri değiştirerek bir kuruluşun verilerinin sahte sürümlerini oluşturur. Gerçekçi ve yapısal olarak benzer değişiklikler oluşturmak için çeşitli teknikler kullanılır. Veriler maskelendikten sonra orijinal veri kümesine erişmeden tersine mühendislik yapamaz veya orijinal veri değerlerine geri dönemezsiniz. Veri maskelemenin 2 temel yöntemi mevcuttur:
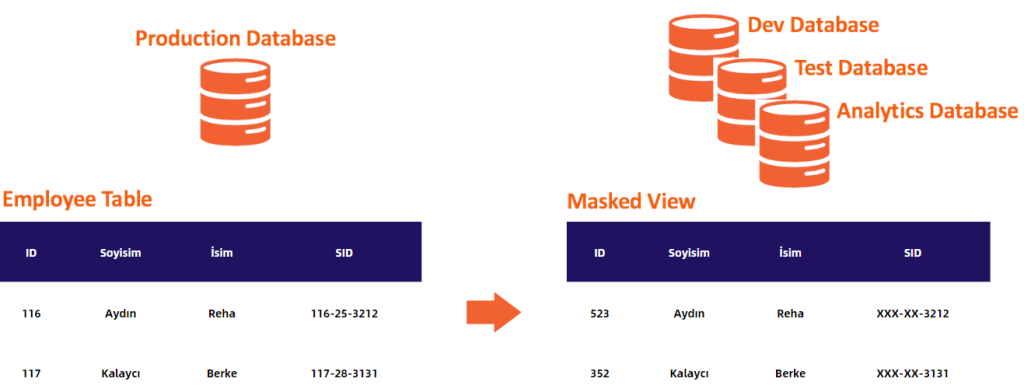
Statik veri maskeleme: Statik veri maskeleme, depolanmadan veya paylaşılmadan önce hassas verilere sabit bir maskeleme kuralları kümesi uygulama işlemidir. Sık sık değişmeyen veya zaman içinde statik kalan veriler için yaygın olarak kullanılır. Kuralları önceden tanımlar ve tutarlı bir şekilde verilere uygularsınız. Bu da birden fazla ortamda tutarlı maskeleme sağlar.
Dinamik veri maskeleme: Dinamik veri maskeleme, maskeleme tekniklerini gerçek zamanlı olarak uygular. Kullanıcılar eriştikçe veya sorguladıkça mevcut hassas verileri dinamik olarak değiştirir. Öncelikli olarak müşteri desteği veya tıbbi kayıt işleme gibi uygulamalarda rol tabanlı veri güvenliğini uygulamak için kullanılır.
Veri Değiştirme (Data Swapping)
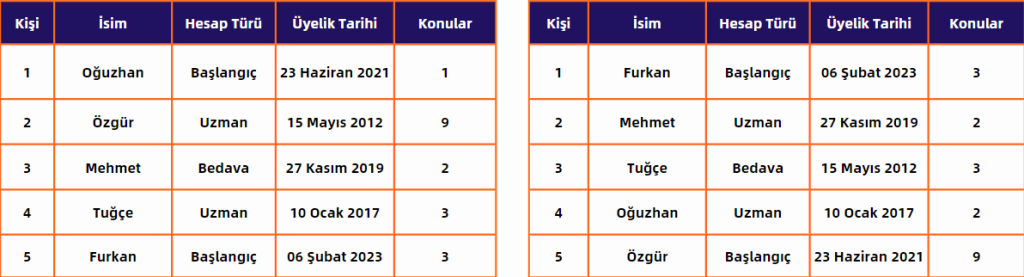
Bu yöntemde, veri setindeki bireylerin kişisel bilgileri, başka bir veri setinden gelen benzer bir örnek ile değiştirilir. Örneğin, bir kullanıcının yaş bilgisi, aynı yaş aralığına sahip başka bir kullanıcının yaş bilgisiyle takas edilebilir. Bu şekilde, orijinal veri setindeki bireylerin mahremiyeti korunurken, genel veri yapısı ve özellikleri korunmuş olur. Veri değiştirme, bireylerin kişisel bilgilerini korumak için etkili bir yol sunar, çünkü orijinal veri setindeki bilgiler yerine benzer ancak farklı bireylerin bilgileri kullanılır fakat takas işlemi için seçilen benzer verilerin, orijinal veri setindeki bilgilerle yeterince benzer olması önemlidir.
Aşağıdaki görselde basit bir Veri Değişim örneği gözlemlenmektedir.
Genelleştirme (Generalization)
Veri genelleştirmede amaç veri doğruluğunun bir ölçüsünü korurken bazı tanımlayıcıları ortadan kaldırmaktır. Veri bir dizi aralığa veya uygun sınırlara sahip geniş bir alana dönüştürülebilir. Örneğin, bir kişinin tam adresini vermek yerine şehrini veya ilçesini belirtebilirsiniz. Bu, sayısal değerler de dahil olmak üzere her türlü veri için yapılabilir. Bu, herhangi birinin verinin kimden geldiğini belirlemesini zorlaştırmak için kasıtlı olarak yapılır.
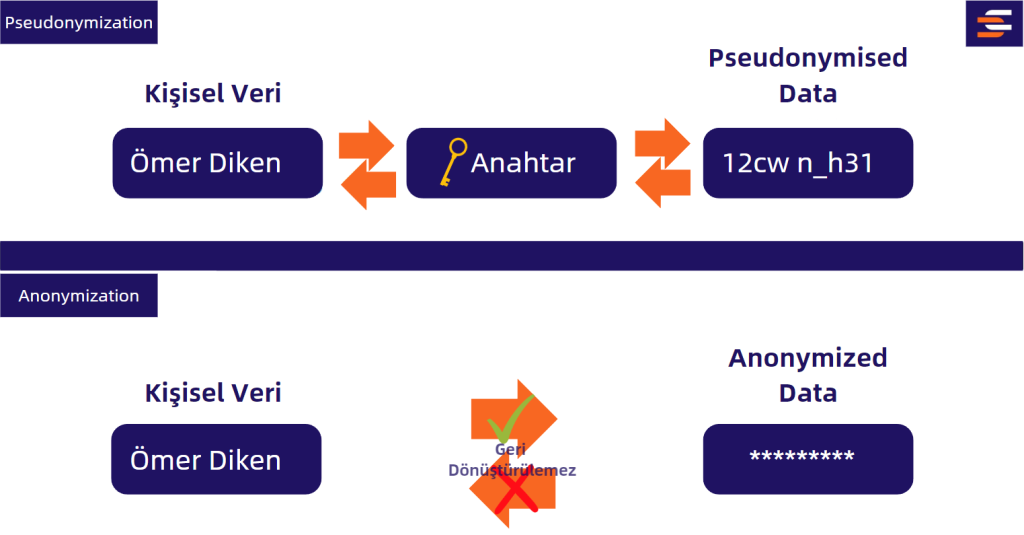
Takma Ad Kullanımı (Pseudonymization)
GDPR, tarafından takma ad kullanımı “kişisel verilerin, ek bilgi kullanılmadan belirli bir veri sahibine atfedilemeyeceği bir şekilde işlenmesi” olarak tanımlanır. Veri takma adlaştırma genellikle bir veri seti bilgisindeki doğrudan tanımlayıcıların “takma adlar” veya yapay tanımlayıcılarla değiştirilerek maskelenmesi sürecini ifade eder. Örneğin, bireylerin e-posta adresleri sayılarla değiştirilirse veriler takma ad olarak değerlendirilebilir; orijinal, doğrudan tanımlayıcı bilgiler kaldırılır, ancak her sayı belirli bir e-posta adresine özeldir ve bu nedenle doğru bilgiye sahip herhangi biri tarafından yeniden bir araya getirilebilir.

Pseudonymization yönteminin veri anonimleştirme tekniklerinden en büyük farkı verilerin bir anahtar vasıtasıyla kullanılabilir ve geri dönüştürülebilir olmasıdır. Anonimleştirme, verileri geri dönülemez şekilde değiştiren ve böylece bir bireyin kimliğinin artık doğrudan veya dolaylı olarak tespit edilemeyeceği bir tekniktir.
Sentetik Veri Üretimi (Synthetic data generation)
Sentetik veri oluşturma, gerçek gibi görünen ancak herhangi bir birey ile ilişkilendirilemeyen sahte veya simüle edilmiş veri yaratma işlemidir. Sentetik veri, algoritmaları test etme, eğitme, analiz yapma ve araştırma amacıyla kullanılabilir.
Örneğin, müşteri demografiklerini analiz etmek istiyorsanız ancak gerçek verilere erişim sağlayamıyorsanız, gerçek gibi görünen sahte müşteri profilleri içeren bir sentetik veri kümesi oluşturabilirsiniz. Sentetik veri oluşturma gizlilik, ürün test süreçleri ve makine öğrenimi süreçlerinde işletmeler için oldukça önemlidir. Test ortamlarında kullanılan müşteri bilgilerinin sızması durumunda şirketler regülasyonlara bağlı şekilde büyük zararlar edebilir bu sebeple sentetik veri oluşturmayla gizlilik endişelerini en aza indirme, şirketlerin sentetik veri üretim yöntemlerine yatırım yapmalarının en önemli nedenlerinden bir tanesidir.
Veri bozulması (Data Perturbation)
Veri bozulması bir veri setindeki değerlerin kasıtlı olarak değiştirilmesi veya rastgele hatalar eklenmesi gibi yöntemleri içeren bir veri gizleme tekniğidir. Veri kümesinde yer alan çeşitli veri noktalarının hatalı olmasını ve bu sayede verinin bir kişiye kadar izlenememesini sağlar. Örneğin, birisinin hesabına giriş yaptığı zamanı gösteren kesin zaman damgalarına sahip bir veri kümeniz varsa, herhangi bir kişinin izini sürmeyi imkansız hale getirmek için rastgele bir miktar gürültü ekleyebilirsiniz.Bu yöntem, özellikle çoklu veri setlerinin birleştirilmesi veya paylaşılması durumlarında kullanıcı gizliliği konusunda önemli bir rol oynar.
Sonuç:
Sonuç olarak, veri anonimleştirme yöntemleri, bilgi güvenliği ve gizliliği konularında büyük önem taşır. Ancak, her bir yöntemin kendi avantajları ve zorlukları bulunmaktadır ve seçilecek yöntem, belirli bir kullanım durumuna ve veri setine bağlı olarak dikkatlice değerlendirilmelidir. Verilerin anonimleştirilmesi, tüm veri güvenliği sorunlarına karşı sihirli bir çözüm olmasa da, kuruluş içerisinde kullanılacak veya üçüncü parti ortamlara taşınacak verilerin güvenliğinde büyük önem taşır. Bu makalede belirtilen çeşitli anonimleştirme yöntemleriyle kurum dışına çıkacak verilerin gizliliğini korurken bu verilerden faydalanabilirsiniz. Ancak veri anonimleştirmeyi doğru bir şekilde uygulamak için doğru teknolojik çözümlere ve alanında uzman kişilerin danışmanlığına ihtiyaç duyabilirsiniz.
Kaynaklar:
